Synchronize MongoDB into Elasticsearch with Logstash JDBC input plugin

Product Manager at Synapticiel, IT & Telecoms Professional, Interested in ML, AI, IoT, BigData, Cyber Security, RA, FMS, Next Generation BSS/OSS, Mobile Money
Logstash does not prvide any native input plugin to connect MongoDB, but it provide a JDBC input plugin, so to sync MongoDB into Elasticsearch all we need is to find the suitable JBBC driver. The one will be showcased in this blog post is developped by DBSchema.
For our test purpose, the following Docker Compose will be used to spin up a MongoDB instance
version: '3.8'
services:
mongodb_container:
image: mongo:latest
environment:
MONGO_INITDB_ROOT_USERNAME: root
MONGO_INITDB_ROOT_PASSWORD: changeme
ports:
- 27017:27017
volumes:
- mongodb_date:/data/db
volumes:
mongodb_date:
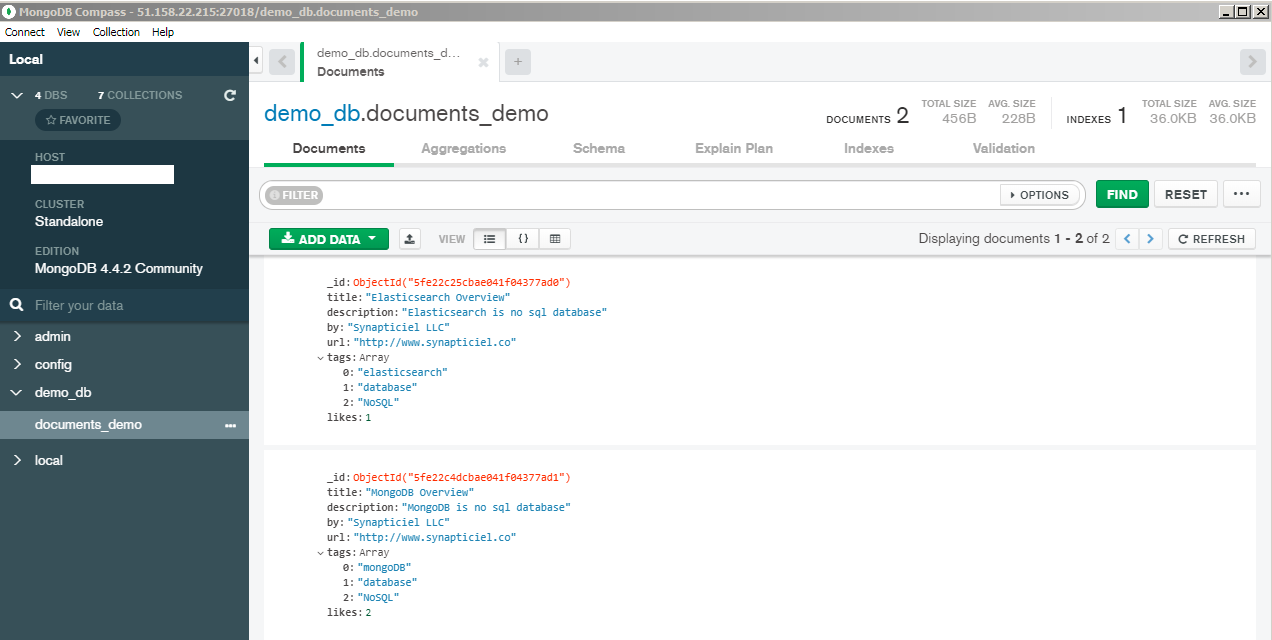
Let's create a new database and a new collection with 2 documents
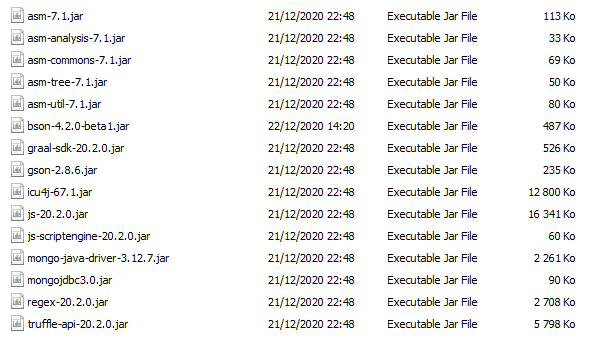
Step 1 : Download JDBC driver Download the dbSchema JDBC driver and extract all jar into a specific folder
Step 2 : Create logstash input setup
input {
jdbc {
jdbc_driver_library => "/opt/driver_mongodb/mongojdbc3.0.jar"
jdbc_driver_class => "Java::com.dbschema.MongoJdbcDriver"
jdbc_connection_string => "jdbc:mongodb://root:changeme@localhost:27017/demo_db?authSource=admin"
jdbc_user => "root"
jdbc_password => "changeme"
schedule => "*/30 * * * * *"
statement => "db.documents_demo.find({});"
}
}
output {
stdout {
codec => rubydebug
}
}
When you run this configuration with logstash you will get the following Warning
[2020-12-22T17:32:10,050][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2020-12-22T17:32:10,463][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
[2020-12-22T17:32:31,234][INFO ][org.mongodb.driver.cluster][main][6d43b2c2d819610b81ecdfc29debdd84a54d72eee0577293c43602ac8614f060] Cluster created with settings {hosts=[localhost:27017], mode=SINGLE, requiredClusterType=UNKNOWN, serverSelectionTimeout='30000 ms', maxWaitQueueSize=500}
[2020-12-22T17:32:31,342][INFO ][org.mongodb.driver.cluster][main][6d43b2c2d819610b81ecdfc29debdd84a54d72eee0577293c43602ac8614f060] Cluster description not yet available. Waiting for 30000 ms before timing out
[2020-12-22T17:32:31,639][INFO ][org.mongodb.driver.connection][main][6d43b2c2d819610b81ecdfc29debdd84a54d72eee0577293c43602ac8614f060] Opened connection [connectionId{localValue:1, serverValue:64}] to localhost:27017
[2020-12-22T17:32:31,743][INFO ][org.mongodb.driver.cluster][main][6d43b2c2d819610b81ecdfc29debdd84a54d72eee0577293c43602ac8614f060] Monitor thread successfully connected to server with description ServerDescription{address=localhost:27017, type=STANDALONE, state=CONNECTED, ok=true, version=ServerVersion{versionList=[4, 4, 2]}, minWireVersion=0, maxWireVersion=9, maxDocumentSize=16777216, logicalSessionTimeoutMinutes=30, roundTripTimeNanos=80013794}
[2020-12-22T17:32:32,452][INFO ][org.mongodb.driver.connection][main][6d43b2c2d819610b81ecdfc29debdd84a54d72eee0577293c43602ac8614f060] Opened connection [connectionId{localValue:2, serverValue:65}] to localhost:27017
[2020-12-22T17:32:37,269][INFO ][logstash.inputs.jdbc ][main][6d43b2c2d819610b81ecdfc29debdd84a54d72eee0577293c43602ac8614f060] (4.458195s) db.documents_demo.find({});
[2020-12-22T17:32:37,397][WARN ][logstash.inputs.jdbc ][main][6d43b2c2d819610b81ecdfc29debdd84a54d72eee0577293c43602ac8614f060] Exception when executing JDBC query {:exception=>"Java::OrgLogstash::MissingConverterException: Missing Converter handling for full class name=org.bson.types.ObjectId, simple name=ObjectId"}
[2020-12-22T17:32:37,520][INFO ][org.mongodb.driver.connection][main][6d43b2c2d819610b81ecdfc29debdd84a54d72eee0577293c43602ac8614f060] Closed connection [connectionId{localValue:2, serverValue:65}] to localhost:27017 because the pool has been closed.
Logstash will through the following exception stating that it was unable to deserialize a field of type ObjectId. MongoDB use by default _id with type org.bson.types.ObjectId to store an auto genareted id of each document (same logic as elasticsearch)
Exception when executing JDBC query {:exception=>"Java::OrgLogstash::MissingConverterException: Missing Converter handling for full class name=org.bson.types.ObjectId, simple name=ObjectId"}
To avoid this issue, we need to ignore the _id in the statement provided to the JDBC driver as follow
statement => "db.documents_demo.find({},{'_id': false});"
The following is a final configuration that can be used with logstash to sync MongDB data into elasticsearch
input {
jdbc {
jdbc_driver_library => "/opt/driver_mongodb/mongojdbc3.0.jar"
jdbc_driver_class => "Java::com.dbschema.MongoJdbcDriver"
jdbc_connection_string => "jdbc:mongodb://root:changeme@localhost:27017/demo_db?authSource=admin"
jdbc_user => "root"
jdbc_password => "changeme"
schedule => "*/30 * * * * *"
statement => "db.documents_demo.find({},{'_id': false});"
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["https://localhost:9200"]
user => "elastic"
password => "changeme"
cacert => "/opt/logstash_mongodb/ca.crt"
ssl => true
index => "mongodb-%{+YYYY-MM-dd}"
action => "index"
}
}
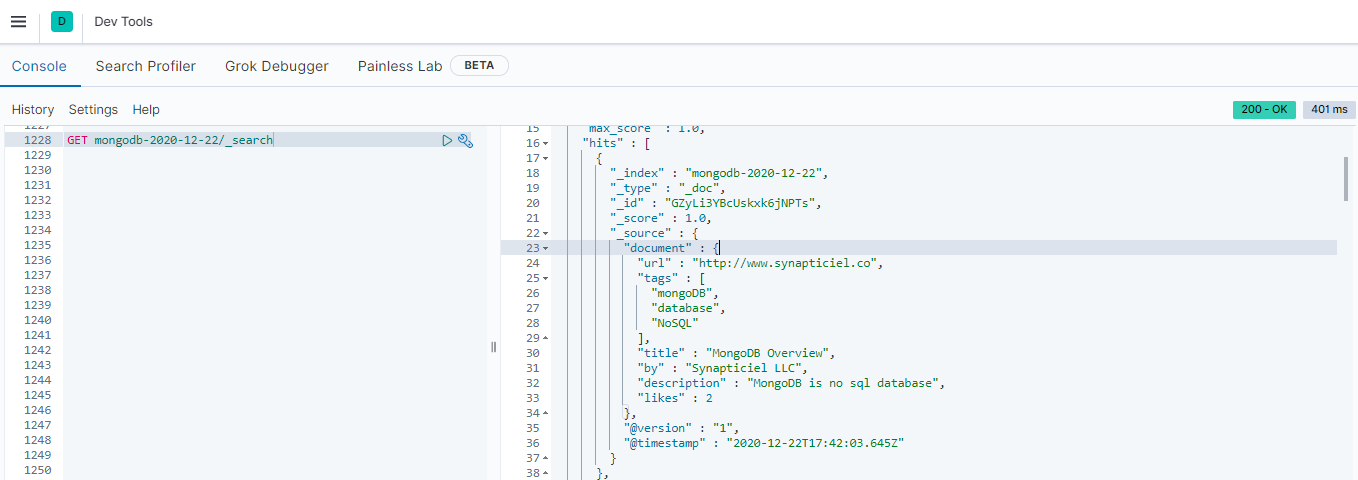
And the job is done, data is already in elasticsearch